domingo, 25 de junio de 2017
Ejercicio de recodificación y cálculo de cuantiles con solución en video
Genérese una base de datos corriendo la sintaxis que sigue:
**************************************************
clear all
set obs 500
set seed 1234
gen años_educ = round(rchi2(5))
gen salario_hora = round(años_edu * 50 + rnormal(0,3))
gen voto = rbinomial(3, 0.40)
replace voto = 12 in 18
label define voto 0 "Izquierda unida" 1 "Derecha patriótica" 2 "Izquierda obrera" 3 "Derecha tradicional"
label values voto voto
gen patrimonio = round((1 - rbeta(200, 3)) * 2000000)
replace patrimonio = patrimonio + 50000 if voto ==1 | voto == 3
**************************************************
Recodifique y rotule la variable años_educ según los siguientes criterios:
Hasta 5 años inclusive: Primaria Incompleta
Hasta 8 años inclusive: Primaria completa
Hasta 11 años inclusive: Ciclo Básico Completo
12 años: Ciclo Superior Completo
Más de 12 años: Universidad o superior
Indique el salario hora medio para cada una de las categorías anteriores.
La variable voto tiene un valor erróneo: 12. Recodifique dicho valor a faltante (lo suponemos un error sin posibilidad de averiguar el valor verdadero), y los restantes valores a las categorías Izquierda y Derecha.
Establezca los quintiles de la variable patrimonio, e indique si tienen una relación significativa con voto dicotomizado de izquierda o de derecha.
Video
sábado, 24 de junio de 2017
recode y xtile. Video
En este video se verán dos maneras que pueden ser usadas para categorizar variables continuas: a través de los comandos recode y xtile.
Se usará la base que se genera corriendo la sintaxis que sigue.
**********************************
clear *
set obs 200
set seed 15863
gen sueldo = rchi2(2) * 10000 + 5000
gen imc = rnormal(25,4)
**********************************
viernes, 23 de junio de 2017
Relaciones bivariadas y recodificación. Ejercicio de revisión 6 (sin solución)
General Social Survey 2016
El archivo
gss2016.dat tiene datos reales. Las variables seleccionadas son parte
de la encuesta llamada "General Social Survey", realizada
en 2016.
ATENCION:
Si desea tratar una variable como ordinal, pero los códigos no
corresponden con ese orden (por ejemplo 1. Bajo 2. Alto y 3.
Intermedio), deberá recodificarla de tal forma que los códigos
queden ordenados (por ejemplo: 1. Bajo 2. Intermedio y 3. Alto). Esta
aclaración se hace por única vez para todo el ejercicio.
Se
desea:
- Estudie la relación entre las variables colscinm (número de cursos científicos que el respondente tomó a nivel universitario) y astrosci (¿es científica la astrología?). Grafique la relación, indique si es significativa y cuál es la fuerza de la asociación. Haga una tabla que indique la media de la cantidad de cursos científicos que tomaron creyentes y no creyentes en la astrología. Comente sobre la relación.
- Estudie la relación entre las variables Zodiac (signo del zodíaco al cual pertenece el respondente) y age (edad). Grafique la relación, indique si la asociación entre estas dos variables es significativa, y haga una tabla con las edades medias y medianas para cada signo. Comente sobre la relación.
- Estudie la relación entre las variables gender1 (género del respondente) y attend (concurrencia a servicios religiosos). Grafique la relación, indique si es significativa y la fuerza de la asociación, genere tabla e indique donde hay excesos de casos notorios si los hay. Comente sobre la relación.
- Estudie la relación entre polviews (orientación política) y poleff16 (desconfianza a las promesas de los congresales). Grafique, indique si la relación es significativa y su fuerza, genere una tabla e indique donde hay excesos relativos de casos notorios si los hay. Comente sobre la relación.
- Estudie la relación entre la variable attend (concurrencia a servicios religiosos) y popespks (el Papa es infalible en materia de fe y de moral). Grafique la relación, indique si es significativa, la fuerza de la asociación y las celdas donde hay notorios excesos relativos de casos). Comente sobre la relación.
- Estudie la relación entre Tvhours (horas por día mirando TV) y educ (año más alto de educación completado por el respondente). Grafique la relación, indique si la asociación entre las variables es significativa y cuál es su fuerza. Comente.
- Estudie la relación entre las variables maeduc (educación de la madre) y paeduc (educación del padre). Grafique la relación, indique si la asociación es significativa y cuál es su fuerza. Comente sobre la relación.
jueves, 22 de junio de 2017
martes, 20 de junio de 2017
Ejercicio de cálculo (sin solución)
Genérese una base corriendo la sintaxis que sigue:
*******************************************
set obs 500
set seed 12324
gen sueldo = runiform() *20000 + 20000
gen hijos = rbinomial(3, 0.50)
*******************************************
Esta base simula información sobre trabajadores. Están sus salarios y su cantidad de hijos.
Un economista está tratando de calcular el rendimiento de dos posibles impuestos.
El primer impuesto propondría no grabar los sueldos de hasta $20000. Los sueldos de más de 20000 y hasta 30000 pagarían un 10%, y los sueldos de más de 30000 un 20%. ¿Cuánto recaudaría este primer impuesto para los trabajadores de la base?
Un segundo impuesto alternativo sería del 20% para los que tienen menos de 2 hijos, y del 15% para los que tienen 2 o más hijos. ¿Cuánto recaudaría este segundo impuesto?
*******************************************
set obs 500
set seed 12324
gen sueldo = runiform() *20000 + 20000
gen hijos = rbinomial(3, 0.50)
*******************************************
Esta base simula información sobre trabajadores. Están sus salarios y su cantidad de hijos.
Un economista está tratando de calcular el rendimiento de dos posibles impuestos.
El primer impuesto propondría no grabar los sueldos de hasta $20000. Los sueldos de más de 20000 y hasta 30000 pagarían un 10%, y los sueldos de más de 30000 un 20%. ¿Cuánto recaudaría este primer impuesto para los trabajadores de la base?
Un segundo impuesto alternativo sería del 20% para los que tienen menos de 2 hijos, y del 15% para los que tienen 2 o más hijos. ¿Cuánto recaudaría este segundo impuesto?
lunes, 19 de junio de 2017
Ejercicio de cálculo con resolución en video.
Este ejercicio simula una base con datos de hombres que subieron sus características de altura, memoria y color de pelo a una aplicación para citas tipo Tinder.
Distintas mujeres desean saber qué hombres tienen los rasgos que ellas desean.
Es un ejercicio para realizar cálculos de variables 0-1. Adicionalmente se practican otros comandos.
Letra del problema
Base
Resolución en video
viernes, 16 de junio de 2017
Ejercicio de cálculo 0-1. Resolución en Video.
En esta entrada se resolverá un problema en donde una serie de mujeres desean saber que citas hay disponibles para ellas en una base de datos de una aplicación tipo Tinder.
La base se creará con la siguiente sintaxis:
*******************************************
clear all
set obs 400
set seed 12546
gen identificacion = _n
gen memoria = rnormal(100, 15)
replace memoria = . in 25/31
gen altura = rnormal(170, 7)
gen colorpelo = int(runiform() *4)+1
replace colorpelo = . in 330/334
gen habla_aleman = int(runiform() *3)+1
label define colorpelo 1 "rubio" 2 "pelirrojo" 3 "castaño" 4 "negro"
label values colorpelo colorpelo
label define habla_aleman 1 "No habla o habla mal" 2 "Bien" 3 "Muy bien"
label values habla_aleman habla_aleman
*******************************************
La base se creará con la siguiente sintaxis:
*******************************************
clear all
set obs 400
set seed 12546
gen identificacion = _n
gen memoria = rnormal(100, 15)
replace memoria = . in 25/31
gen altura = rnormal(170, 7)
gen colorpelo = int(runiform() *4)+1
replace colorpelo = . in 330/334
gen habla_aleman = int(runiform() *3)+1
label define colorpelo 1 "rubio" 2 "pelirrojo" 3 "castaño" 4 "negro"
label values colorpelo colorpelo
label define habla_aleman 1 "No habla o habla mal" 2 "Bien" 3 "Muy bien"
label values habla_aleman habla_aleman
*******************************************
Letra del problema:
La
base adjunta ser de una app de citas, y tiene datos de hombres
interesados. Se pide:
- Indique cuántas variables y cuántos casos hay en la base.
- Indique si hay faltantes, en qué variables los hay, y cuántos.
- Mariela desea conocer personas entre 170 y 185 cm de altura (ambos extremos incluidos), con color de pelo rubio o castaño. Indique cuántas personas cumplen con las condiciones de Mariela.
- Haga un listado de 10 de personas que cumplan estas condiciones, en orden creciente de Identificación. El listado tendrá las variables altura, color de pelo e Identificación.
- Helena desea conocer personas que hablen alemán bien o muy bien, y cuya memoria esté en el séptimo decil o superior. Indique cuántas personas cumplen con las condiciones de Helena.
- Haga un listado de 10 de las personas que cumplan estas condiciones, en orden creciente de Identificación. El listado tendrá las variables Habla_aleman, decil de memoria e identificación.
- Natalia desea conocer personas con un color de pelo que no sea rubio y con altura superior a 175 cm. Indique cuántas personas cumplen con las condiciones de Natalia.
- Haga un listado de 10 de estas personas, en orden creciente de identificación. Las variables serán color de pelo, altura e identificacion.
- Indique cuántos hombres interesan simultáneamente a Mariela, Helena y Natalia.
jueves, 15 de junio de 2017
Usos adicionales de los comandos generate y replace. Cálculo 0-1. _n. Video
En este video se mostrará cómo crear variables dummy (o variables binarias, o variables indicador: son nombres sinónimos). Estas son variables que toman el valor 1 cuando se cumplen ciertas condiciones o 0 si no se cumplen.
Por ejemplo, podemos generar una variable llamada hombre hipertenso que tome el valor 1 en el caso de hombres hipertensos y 0 en otras situaciones.
Si tuvieramos las variables sexo (1 hombre, 2 mujer) y altura (en cm) podríamos generar la variable hombre alto para hombres de más de 180 cm:
gen hombre_alto = sexo == 1 & altura > 180
Otro uso que se mostrará es la generación de números consecutivos, por ejemplo:
gen numero_caso = _n
El comando anterior crea una variable llamada numero_caso que toma los valores consecutivos 1, 2, 3, etc.
Video
Por ejemplo, podemos generar una variable llamada hombre hipertenso que tome el valor 1 en el caso de hombres hipertensos y 0 en otras situaciones.
Si tuvieramos las variables sexo (1 hombre, 2 mujer) y altura (en cm) podríamos generar la variable hombre alto para hombres de más de 180 cm:
gen hombre_alto = sexo == 1 & altura > 180
Otro uso que se mostrará es la generación de números consecutivos, por ejemplo:
gen numero_caso = _n
El comando anterior crea una variable llamada numero_caso que toma los valores consecutivos 1, 2, 3, etc.
Video
sábado, 10 de junio de 2017
Etiquetado de variable, y de los valores que puede tomar la variable. Video
En el video adjunto se mostrará cómo etiquetar
1) variables
2) valores que toman las variables
Se trabajará con la base que genera ejecutar la siguiente sintaxis:
************************
clear all
set obs 20
set seed 3526
gen ppol = trunc(runiform() *4)
tab1 ppol
************************
La sintaxis anterior genera una variable llamada ppol, que será etiquetada "Partido Político que votó en las últimas elecciones".
Se mostrará cómo se etiquetan variables con la ayuda del comando label variable.
Hay 4 respuestas posibles: 0, 1, 2 y 3.
Estos valores representan a distintos partidos:
0 "Partido del Norte"
1 "Partido Democrático"
2 "Partido Agrícola"
3 "Partido Obrero".
Se mostrará cómo se etiquetan estos valores, con ayuda de los comandos label define y label values.
Video
martes, 30 de mayo de 2017
Comandos generate y replace. Video
En este video se verá el principal comando para crear nuevas variables, generate, y el principal comando para modificar valores de variables ya creadas, replace.
Asimismo se mostrarán los comandos label variable, label define y label values, que permiten rotular las variables y los valores que estas pueden tomar.
Se trabajará sobre la base de datos que se genera ejecutando la sintaxis que sigue:
*****************************************************
cls
clear all
set obs 200
set seed 1234
gen salario_hora_pesos = (rchi2(2) + 5) * 30
gen desocupacion = rbinomial(1, 0.10)
label define desocupacion 0 "Ocupado" 1 "Desocupado"
label values desocupacion desocupacion
replace salario_hora = . if desocupacion == 1
gen altura_pulgadas = round(rnormal(68, 3))
gen peso_kg = round(altura *2.5 - 100 + rnormal(0, 7))
gen ppol = trunc((runiform() *4)+ 1 )
gen horas_trab = rnormal(140, 5) if desocupacion == 0
******************************************************
Para ilustrar el uso de los comandos, se ejecutarán las instrucciones que siguen:
Asimismo se mostrarán los comandos label variable, label define y label values, que permiten rotular las variables y los valores que estas pueden tomar.
Se trabajará sobre la base de datos que se genera ejecutando la sintaxis que sigue:
*****************************************************
cls
clear all
set obs 200
set seed 1234
gen salario_hora_pesos = (rchi2(2) + 5) * 30
gen desocupacion = rbinomial(1, 0.10)
label define desocupacion 0 "Ocupado" 1 "Desocupado"
label values desocupacion desocupacion
replace salario_hora = . if desocupacion == 1
gen altura_pulgadas = round(rnormal(68, 3))
gen peso_kg = round(altura *2.5 - 100 + rnormal(0, 7))
gen ppol = trunc((runiform() *4)+ 1 )
gen horas_trab = rnormal(140, 5) if desocupacion == 0
******************************************************
Para ilustrar el uso de los comandos, se ejecutarán las instrucciones que siguen:
Llevar la altura, que está en
pulgadas, a metros. Se recuerda que un metro son 39,37 pulgadas
Calcular el índice de masa corporal:
IMC = peso en kilos / (altura en metros) ^2
Calcular el sueldo mensual = salario
hora * horas trabajadas
Calcular impuesto1 =
10% del sueldo si el sueldo es menor a
23000,
20% si es de 23000 o más y menos de de
27000,
30% si es de 27000 o más.
Calcular impuesto2 =
15% del sueldo si el salario es menor a
25000
miércoles, 24 de mayo de 2017
Ejercicio de relaciones bivariadas. Revisión 2 (sin solución)
Ejercicio
de relaciones bivariadas, previa exploración univariada
Se trabajará con la base Mundo95.dta, que se adjunta.
Exploración univariada
Relaciones bivariadas
Se trabajará con la base Mundo95.dta, que se adjunta.
- Cuántas variables tiene la base?
- Cuántos casos tiene la base?
Exploración univariada
- Explore la variable relig gráficamente, haciendo que las
categorías más frecuente queden primero.
- Explore la variable religión mediante una tabla de
frecuencias, haciendo que las categorías más numerosas queden
primero.
- Qué observa sobre dicha variable? Comente.
- Explore la variable población gráficamente.
- La población, ¿tiene una distribución aproximadamente
normal? ¿Hay outliers muy marcados?
- Con ayuda del comando de usuario “extremes”, indique si
hay outliers en la variable poblac y a qué países corresponden.
- Según la forma de la distribución, pida la media y la
desviación estándar o bien un resumen de 5 puntos.
- ¿Qué aspectos le llaman más la atención de esta
distribución?
- Explore gráficamente la variable mortalidad infantil.
- ¿Es una distribución aproximadamente normal? ¿Es simétrica
o asimétrica? ¿Tiene outliers muy marcados?
- Si los hay, con ayuda del comando de usuario “extremes”,
indique sus valores y a qué países corresponden.
- Dada la forma de la distribución, ¿es mejor representarla
mediante media y desvío estándar o mediante un resumen de 5
puntos?
- Pida la representación numérica correspondiente.
Relaciones bivariadas
- Sólo para OCDE y Africa, grafique la relación entre región y clima, con ayuda del programa de usuario catplot. Si es necesario edítese la gráfica para tornarla más legible.
- Con el programa de usuario “spineplot” grafique con él
la relación entre región y clima (solo para OCDE y Africa).
- ¿Cuál de las dos gráficas le parece más adecuada en esta
ocasión? Comente.
- Solo para Ocde y Africa, estudie la relación anterior
mediante una tabla de porcentajes y de frecuencias absolutas.
- ¿Cuáles son los aspectos más destacados que muestra la
tabla?
- Estudie gráficamente la esperanza de vida femenina por
región. Qué región muestra mayor esperanza de vida y cuál menor?
¿Hay outliers marcados?
- Estudie a nivel numérico la relación entre esperanza de
vida femenina y región. Si las distribuciones de la esperanza de
vida femenina son aproximadamente normales en las regiones utilice
la media y la desviación estándar. Si son fuertemente asimétricas
utilice resúmenes de 5 puntos para cada región.
- Con ayuda del comando “extremes” identifique los valores
más extremos de la esperanza de vida femenina y a qué país
pertenecen.
- Estudie gráficamente la relación entre esperanza de vida masculina y esperanza de vida femenina. ¿La relación es aproximadamente lineal? ¿Hay outliers marcadamente separados del resto de la nube de puntos?
martes, 23 de mayo de 2017
Ejercicio con comando de usuario "extremes" (sin solución)
Abra la base census.dta que viene con la instalación de Stata. Allí tendrá información de los años 1980 sobre 50 estados norteamericanos.
- En dicha base, ¿cuáles son los tres estados más poblados?
- ¿Cuáles son los tres estados más poblados de la región Sur?
- Indique el nombre, la región y la cantidad de divorcios del estado con el mayor número de casamientos.
- Indique los nombres de los cuatro estados que tienen las dos edades medianas más altas y más bajas.
- Indique los nombres de los cuatro estados que tienen las dos edades medianas más altas y más bajas en la región Oeste.
lunes, 22 de mayo de 2017
Comando de usuario "extremes". Video.
El comando de usuario "extremes" nos da los valores más altos y más bajos de una variable.
Por ejemplo, si tenemos una base con la variable altura, el comando
extremes altura
nos da los 5 casos más bajos y los 5 más altos.
Si quisiéramos, p.e., los 10 más altos y los 10 más bajos, escribiríamos
extremes altura, n(10)
extremes altura, n(10)
Si quisiéramos las 6 mujeres más altas, el comando sería similar a este:
extremes altura if sexo == "mujer", high n(6)
extremes altura if sexo == "mujer", high n(6)
Si quisiéramos la altura de las 4 mujeres más bajas, el comando sería:
extremes altura if sexo == "mujer", low n(4)
Y si quisiéramos saber el peso de las 10 personas más altas, pediríamos:
extremes altura peso, high(10)
Nótese que los valores extremos se buscan para altura, y simplemente se da el peso para esas personas más altas. No se dan aquí los pesos más altos, sino los correspondientes a las personas más altas.
Si quisiéramos saber cuáles son los 5 países con mayor población, los pediríamos así:
extremes poblacion nombre, high n(5)
sábado, 20 de mayo de 2017
martes, 16 de mayo de 2017
Tabla sintética sobre relaciones bivariadas
Esquema que indica principales tipos de relaciones bivariadas, con sus gráficas, tablas, pruebas de significación y medidas de asociación.
Tabla sintética
lunes, 15 de mayo de 2017
Ejercicio de relaciones entre variables ordinales (sin solución)
Corra la sintaxis que sigue, y se creará base de datos ficticia con datos de pacientes. Las variables serán calidad de vida, tiempo desde el inicio de la enfermedad, sexo y tipo de tratamiento.
************************************************
clear all
set seed 1235
set obs 300
gen calidad_vida = rbinomial(3, 0.60)
label define calidad_vida 0 "Baja" 1 "Media" 2 "Media Alta" 3 "Alta"
label values calidad_vida calidad_vida
gen tiempo_desde = 3 - calidad_vida + 1*(runiform() < 0.30)
replace tiempo = 2 if tiempo > 2
label variable tiempo "Tiempo desde inicio enfermedad"
label define tiempo 0 "Menos de un año" 1 "Entre 1 y 4 años" 2 "Más de 4 años"
label values tiempo tiempo
replace tiempo = . in 24/28
gen tipo_tratamiento = trunc(runiform()*2)
label define tipo 0 "Estándar" 1 "Intensivo"
label values tipo tipo
gen sexo = 0 if calidad_vida < 2
replace sexo = 1 if calidad_vida > 2
replace sexo = trunc(runiform() * 2) if runiform() < 0.30
replace sexo = . in 15/16
label define sexo 1 "Mujer" 0 "Hombre"
label values sexo sexo
************************************************
Exploración de la base
¿Cuántos casos tiene la base?
¿Hay datos faltantes? Si los hay, indique cuántos son y en qué variables
Explore las variables. Indique si son continuas o categóricas. Si son categóricas, indique si son ordenadas o no ordenadas.
Tiempo desde inicio de enfermedad y calidad de vida.
Grafique la relación entre estas dos variables. Interprete la gráfica. A mayor tiempo desde el inicio de la enfermedad, hay mayor o menor calidad de vida?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber si existe una relación del tipo "a más tiempo desde el inicio mayor calidad de vida" o por el contrario del tipo "a más tiempo desde el inicio de la enfermedad menor calidad de vida", pida la medida de asociación tau b.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
Calidad de vida y tipo de tratamiento.
El tipo de tratamiento es una variable dicotómica. Estas variables, por sus características matemáticas, siempre pueden ser interpretadas como ordinales. Aquí el tipo de tratamiento puede ser estándar o intensivo. Podría considerarse legítimamente como una ordenación en el grado de intensidad.
Grafique la relación entre estas dos variables. Interprete la gráfica. El tratamiento intensivo, ofrece mayor, menor o igual calidad de vida que el tratamiento estándar?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber el grado de asociación entre estas dos variables, esto es, para saber si cuando crece la intensidad del tratamiento crece, decrece o se mantiene igual la calidad de vida, pida el coeficiente de asociación tau b e interprételo.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
Calidad de vida y sexo
Sexo es una variable dicotómica. Estas variables, por sus características matemáticas, siempre pueden ser interpretadas como ordinales.
Grafique la relación entre estas dos variables. Interprete la gráfica. Las mujeres, ¿tienen mayor, igual o menor calidad de vida que los hombres?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber el grado de asociación entre estas dos variables, pida el coeficiente de asociación tau b e interprételo.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
************************************************
clear all
set seed 1235
set obs 300
gen calidad_vida = rbinomial(3, 0.60)
label define calidad_vida 0 "Baja" 1 "Media" 2 "Media Alta" 3 "Alta"
label values calidad_vida calidad_vida
gen tiempo_desde = 3 - calidad_vida + 1*(runiform() < 0.30)
replace tiempo = 2 if tiempo > 2
label variable tiempo "Tiempo desde inicio enfermedad"
label define tiempo 0 "Menos de un año" 1 "Entre 1 y 4 años" 2 "Más de 4 años"
label values tiempo tiempo
replace tiempo = . in 24/28
gen tipo_tratamiento = trunc(runiform()*2)
label define tipo 0 "Estándar" 1 "Intensivo"
label values tipo tipo
gen sexo = 0 if calidad_vida < 2
replace sexo = 1 if calidad_vida > 2
replace sexo = trunc(runiform() * 2) if runiform() < 0.30
replace sexo = . in 15/16
label define sexo 1 "Mujer" 0 "Hombre"
label values sexo sexo
************************************************
Exploración de la base
¿Cuántos casos tiene la base?
¿Hay datos faltantes? Si los hay, indique cuántos son y en qué variables
Explore las variables. Indique si son continuas o categóricas. Si son categóricas, indique si son ordenadas o no ordenadas.
Tiempo desde inicio de enfermedad y calidad de vida.
Grafique la relación entre estas dos variables. Interprete la gráfica. A mayor tiempo desde el inicio de la enfermedad, hay mayor o menor calidad de vida?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber si existe una relación del tipo "a más tiempo desde el inicio mayor calidad de vida" o por el contrario del tipo "a más tiempo desde el inicio de la enfermedad menor calidad de vida", pida la medida de asociación tau b.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
Calidad de vida y tipo de tratamiento.
El tipo de tratamiento es una variable dicotómica. Estas variables, por sus características matemáticas, siempre pueden ser interpretadas como ordinales. Aquí el tipo de tratamiento puede ser estándar o intensivo. Podría considerarse legítimamente como una ordenación en el grado de intensidad.
Grafique la relación entre estas dos variables. Interprete la gráfica. El tratamiento intensivo, ofrece mayor, menor o igual calidad de vida que el tratamiento estándar?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber el grado de asociación entre estas dos variables, esto es, para saber si cuando crece la intensidad del tratamiento crece, decrece o se mantiene igual la calidad de vida, pida el coeficiente de asociación tau b e interprételo.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
Calidad de vida y sexo
Sexo es una variable dicotómica. Estas variables, por sus características matemáticas, siempre pueden ser interpretadas como ordinales.
Grafique la relación entre estas dos variables. Interprete la gráfica. Las mujeres, ¿tienen mayor, igual o menor calidad de vida que los hombres?
Genere una tabla de porcentajes. Identifique las celdas con exceso de casos. Interprétela y diga si confirma lo hallado mediante la gráfica.
Para saber el grado de asociación entre estas dos variables, pida el coeficiente de asociación tau b e interprételo.
Pida finalmente una prueba de significación para tau b e interprete los resultados.
miércoles, 10 de mayo de 2017
Relaciones bivariadas: variables ordinal - ordinal. Video
En este video se verán relaciones entre variables categóricas ordinales. Son variables entre cuyas categorías existe un claro orden. Por ejemplo: máximo nivel educativo alcanzado, con las opciones de respuesta primaria, secundaria, universidad y posgrado. Otro ejemplo: prestigio del trabajo ejercido: bajo, medio o alto.
Una pregunta habitual es si cuando aumenta el valor de una variable (por ejemplo más educación), aumenta el valor de la otra (por ejemplo más prestigio). Para ver el grado de asociación entre dos variables ordinales, en Stata se emplea habitualmente el coeficiente taub.
A continuación sigue una sintaxis que da origen a una base de datos ficticia sobre libros, con la cual se trabajará en el video.
*****************************************
clear all
set obs 300
set seed 123456
gen precio = rbinomial(2,0.5)
label variable precio "Precio del libro"
label define precio 0 "Bajo" 1 "Medio" 2 "Alto"
label values precio precio
gen prestigio = precio + round(rnormal(0,1))
label variable prestigio "Prestigio del autor"
label define prestigio 0 "Poco" 1 "Medio" 2 "Mucho"
label values prestigio prestigio
replace prestigio = 0 if prestigio < 0
replace prestigio = 2 if prestigio > 2
gen paginas = 1 if precio == 0
replace paginas = 1 if precio == 2
replace paginas = trunc(runiform()*3) if precio == 1
label define paginas 0 "Pocas" 1"Medias" 2"Muchas"
label values paginas paginas
gen sexo = prestigio
replace sexo = 1 if sexo == 2
replace sexo = round(runiform()) if runiform() < 0.30
label variable sexo "Sexo del autor"
label define sexo 0 "Hombre" 1 "Mujer"
label values sexo sexo
*******************************************
Video
Una pregunta habitual es si cuando aumenta el valor de una variable (por ejemplo más educación), aumenta el valor de la otra (por ejemplo más prestigio). Para ver el grado de asociación entre dos variables ordinales, en Stata se emplea habitualmente el coeficiente taub.
A continuación sigue una sintaxis que da origen a una base de datos ficticia sobre libros, con la cual se trabajará en el video.
*****************************************
clear all
set obs 300
set seed 123456
gen precio = rbinomial(2,0.5)
label variable precio "Precio del libro"
label define precio 0 "Bajo" 1 "Medio" 2 "Alto"
label values precio precio
gen prestigio = precio + round(rnormal(0,1))
label variable prestigio "Prestigio del autor"
label define prestigio 0 "Poco" 1 "Medio" 2 "Mucho"
label values prestigio prestigio
replace prestigio = 0 if prestigio < 0
replace prestigio = 2 if prestigio > 2
gen paginas = 1 if precio == 0
replace paginas = 1 if precio == 2
replace paginas = trunc(runiform()*3) if precio == 1
label define paginas 0 "Pocas" 1"Medias" 2"Muchas"
label values paginas paginas
gen sexo = prestigio
replace sexo = 1 if sexo == 2
replace sexo = round(runiform()) if runiform() < 0.30
label variable sexo "Sexo del autor"
label define sexo 0 "Hombre" 1 "Mujer"
label values sexo sexo
*******************************************
Video
domingo, 30 de abril de 2017
Ejercicio de relaciones entre variables categóricas no ordenadas (sin solución)
Córrase la sintaxis que sigue y se creará una base de datos.
***************************************************
clear all
set obs 180
set seed 1625
gen editorial= rbinomial(2, 0.40)
label define editorial 0 "FCU" 1"McGrawHill" 2 "Prentice Hall"
label values editorial editorial
gen ilustraciones = rbinomial(2, 0.30) if editorial ==2
replace ilustraciones = rbinomial(2, 0.60) if editorial ==1
replace ilustraciones = rbinomial(2, 0.87) if editorial ==0
label define ilustraciones 0 "Ninguna" 1 "Pocas" 2 "Muchas"
label values ilustraciones ilustraciones
gen color_tapa = trunc(runiform()*4) + 1
label define color_tapa 1 "Amarillo" 2 "Verde" 3 "Rojo" 4 "otro"
label values color_tapa color_tapa
tab2 editorial ilustraciones
tab2 editorial color_tapa
***************************************************
Relación editorial - ilustraciones
- Haga una tabla cruzada que vincule las variables editorial e ilustraciones, y preste atención a cuántos casos hay en cada celda.
- Asumiendo que estamos en presencia de una muestra aleatoria extraída de un universo mucho más amplio, ¿el tamaño de las celdas permite hacer una prueba de significación de chi cuadrado o deberá preferirse el test exacto de Fisher?
- Haga el test que corresponda e indique si la relación es significativa.
- Haga una tabla de porcentajes. Se utilizará la variable editorial como variable independiente e ilustraciones como dependiente. Indique en qué celdas hay excesos relativos de casos. Interprete la tabla.
- Haga una gráfica de tipo spineplot e interprétela.
- Indique la fuerza de la asociación utilizando la V de Cramer. Comente.
****
Relación editorial - color de tapa
- Haga una tabla cruzada que vincule las variables editorial y color de tapa. Preste atención a cuántos casos hay en cada celda.
- Asumiendo que estamos en presencia de una muestra aleatoria extraída de un universo mucho más amplio, ¿el tamaño de las celdas permite hacer una prueba de significación de chi cuadrado o deberá preferirse el test exacto de Fisher?
- Haga el test que corresponda e indique si la relación es significativa.
- Haga una tabla de porcentajes. Se utilizará la variable editorial como variable independiente e color de tapa como dependiente. Indique en qué celdas hay excesos relativos de casos.
- Haga una gráfica de tipo spineplot e interprétela.
- Indique la fuerza de la asociación utilizando la V de Cramer. Comente
martes, 25 de abril de 2017
Relaciones bivariadas entre dos variables categóricas no ordenadas. Tab2 y spineplot. Video
Probablemente la herramienta más útil para estudiar relaciones entre dos variables categóricas no ordenadas sea la tabla de porcentajes.
Imaginemos que en una encuesta deseamos estudiar la relación entre sexo y afiliación a sindicato, y que pensemos que el sexo puede influir en la decisión de afiliarse. Realizaríamos esta tabla.


En la tabla anterior nos encontraríamos que no hay asociación entre estas variables: ser hombre o ser mujer no torna más probable estar afiliado. Esta es una NO ASOCIACION perfecta. No hay nada de asociación.
*
Imaginemos ahora que queremos estudiar la relación entre sexo y gusto por el boxeo, y que una encuesta arrojase los siguientes resultados.
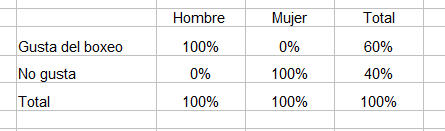

En esta tabla la ASOCIACION es perfecta, porque la diferencia entre quienes gustan del boxeo es máxima entre sexos: gusta al 100% de los hombres y al 0% de las mujeres.
Usualmente se ven situaciones intermedias.
Ambas tablas tienen la variable dependiente (sexo) en las columnas y se pide el porcentaje por columnas. Luego se comparan los porcentajes a través.
Si hay relación en una muestra y queremos saber si podemos descartar la hipótesis nula de no asociación en el universo, tenemos dos pruebas de significación: chi cuadrado y test exacto de Fisher. La prueba de chi cuadrado requiere que menos del 20% de las celdas tengan cinco casos o menos. Si no se diera esto, recurrimos al test exacto de Fisher.
Una buena manera de graficar la relación entre dos variables categóricas es con el llamado diagrama de mosaico. Podemos efectuarlos con ayuda del programa de usuario spineplot.
La fuerza de la asociación se puede medir con la V de Cramer, en donde 0 significa no asociación, y +1 y -1 significan asociaciones perfectas (según la diagonal que concentre los casos será +1 o -1).
Se mostrará como ejecutar estos análisis en el video que sigue.
Video
jueves, 20 de abril de 2017
Ejercicio de comparación de medias (o medianas) con Anova, Kruskal Wallis y prueba de la mediana (sin solución)
Ejecútese la sintaxis que sigue y se dispondrá de una base de datos para realizar el ejercicio.
************************************************
clear all
set obs 200
set seed 1234
gen dieta = trunc(runiform()*3)
label define dieta 0 "Bajas calorías" 1 "Bajos carbohidratos" 2 "Bajas grasas"
label values dieta dieta
replace dieta = 1 if dieta == 2 & runiform() < 0.5
gen perdida_peso = rnormal(7,2) if dieta == 0
replace perdida_peso = rnormal(15, 5) if dieta == 1
replace perdida_peso= rnormal(8,1) if dieta == 2
gen colesterol = rnormal(180, 4)
gen edad = round(rnormal (50, 4))
replace edad = edad + 6 if dieta == 1
*************************************************
En esta base hay cuatro variables:
Se asume que tres grupos de personas fueron sujetos a diferentes dietas durante algún tiempo, y que al fin del período se miden la pérdida de peso y el nivel de colesterol. Asimismo se registró la edad de los participantes.
Se pide al estudiante:
Colesterol:
Edad
Pérdida de peso
************************************************
clear all
set obs 200
set seed 1234
gen dieta = trunc(runiform()*3)
label define dieta 0 "Bajas calorías" 1 "Bajos carbohidratos" 2 "Bajas grasas"
label values dieta dieta
replace dieta = 1 if dieta == 2 & runiform() < 0.5
gen perdida_peso = rnormal(7,2) if dieta == 0
replace perdida_peso = rnormal(15, 5) if dieta == 1
replace perdida_peso= rnormal(8,1) if dieta == 2
gen colesterol = rnormal(180, 4)
gen edad = round(rnormal (50, 4))
replace edad = edad + 6 if dieta == 1
*************************************************
En esta base hay cuatro variables:
- Dieta (de bajas calorías, de bajos carbohidratos y de bajas grasas)
- Pérdida de peso
- Colesterol
- Edad
Se asume que tres grupos de personas fueron sujetos a diferentes dietas durante algún tiempo, y que al fin del período se miden la pérdida de peso y el nivel de colesterol. Asimismo se registró la edad de los participantes.
Se pide al estudiante:
Colesterol:
- Grafique la relación entre colesterol y dieta. ¿Las gráficas muestran una distribución razonablemente simétrica, que sugiera normalidad? ¿Las varianzas son aparentemente iguales? ¿Las medias tienen grandes diferencias?
- Ejecute una prueba de Anova. ¿Qué dice el test de Bartlett sobre las varianzas: que son estadísticamente significativas o no?
- Si las diferencias entre las varianzas no son estadísticamente significativas interprete Anova. ¿Hay diferencias significativas entre las medias?
- Si hay diferencias significativas entre las medias, indique entre qué dietas mediante una prueba post-hoc
Edad
- Grafique la relación entre edad y dieta. ¿Las gráficas muestran una distribución más o menos simétrica, que sugiera normalidad? ¿Las varianzas son aproximadamente iguales? ¿Las medias parecen tener diferencias importantes?
- Efectúe la prueba de Anova. ¿Qué dice el test de Bartlett sobre las varianzas: que son estadísticamente significativas o no?
- Si las diferencias entre las varianzas no son estadísticamente significativas interprete Anova. ¿Hay diferencias significativas entre las medias?
- Si hay diferencias significativas entre las medias, efectúe análisis post-hoc, para ver entre qué medias hay diferencias.
Pérdida de peso
- Grafique la relación entre pérdida de peso y dieta. ¿Las gráficas muestran una distribución más o menos simétrica que sugiera normalidad? ¿Las varianzas son aproximadamente iguales? ¿Las medias tienen grandes diferencias?
- Aún si hay fuertes diferencias entre las varianzas, ejecute Anova, simplemente para ver si el resultado del test de Bartlett. ¿Indica que las diferencias entre las varianzas es estadísticamente significativa?
- Si las diferencias entre las varianzas se muestran estadísticamente significativas, abandone el test de Anova y efectúe dos pruebas no paramétricas: la de Kruskall Wallis y la prueba de la mediana.
- Indique qué conclusiones saca de estas pruebas no paramétricas y si coincide con lo que esperaba a partir de la gráfica para ver la relación entre estas variables (pérdida de peso y dieta).
sábado, 15 de abril de 2017
Relación entre una variable continua y una categórica con tres valores o más. Video.
Imaginemos que estudiantes se han inscripto en un curso y han sido asignados a tres docentes distintos, y que se desea saber si los puntajes que obtienen los estudiantes de los tres docentes son todos iguales o no.
Prueba de ANOVA
Para saber si las diferencias que de estos tres grupos son significativas se puede efectuar la prueba de ANOVA (por ANalisys Of VAriance, análisis de varianza). La hipótesis nula en la prueba de Anova es que las medias de los distintos grupos son iguales entre sí, y la hipótesis alternativa es que al menos alguna de las medias es distinta de las otras.
La prueba de Anova tiene tres supuestos:
- las observaciones son independientes
- cada uno de los grupos tiene igual varianza
- las distribuciones de la variable continua son normales dentro de cada uno de los grupos.
La normalidad de la variable continua pierde importancia si los grupos son grandes. Llamaremos grande a un grupo si tiene 30 observaciones o más (algunos estadísticos se inclinan por otras cifras, pero 30 es un criterio más o menos usual).
La igualdad de varianzas en cada uno de los grupos pierde importancia si todos los grupos tienen igual tamaño.
Ahora bien, si las varianzas son fuertemente desiguales y son distintos los tamaños de los grupos, Anova es poco confiable. Mejor realizar una alternativa no paramétrica.
Si la prueba de Anova es significativa, se sabe que al menos uno de los grupos es significativamente distinto de los otros. Pero ¿cuál es significativamente distinto de cuál? Para esto están las llamadas pruebas post-hoc, que comparan la media de cada grupo con la media de los otros grupos. Stata ofrece tres pruebas post-hoc: Bonferroni, Scheffe y Sidak.
¿Como pedir una prueba de Anova de una vía en Stata?
Una buena forma, mediante sintaxis, es la que sigue.
oneway var_continua var_categorica, tab bonf
Otra manera es llamando al cuadro de diálogo con
db oneway
En ese cuadro, la variable de respuesta es la variable continua, y la variable factor es la variable categórica.
Por ejemplo, si quisieramos comparar salarios medios entre razas, podríamos pedir:
oneway salario raza, tab bonf
la opción tab genera una tabla con las medias y las frecuencias de los diferentes grupos.
la opción bonf nos procura un análisis de bonferroni.
En el ejemplo anterior supusimos que se cumplen los supuestos de Anova. ¿Pero que pasa si claramente no se cumplen? Para esto están las pruebas no paramétricas.
Pruebas no paramétricas: Kruskall Wallis y prueba de la mediana
Cuando no están dados los supuestos del análisis de Anova, se pueden efectuar las pruebas de Kruskall Wallis o la prueba de la mediana.
La prueba de la mediana testea si las diferencias son significativas. Necesita diferencias más marcadas que otras pruebas para considerar que hay evidencias significativas.
La prueba de Kruskal Wallis compara rangos. Es similar, aunque no idéntica, a la prueba de la mediana. Es más sensible.
Para Kruskal Wallis:
kwallis wage, by(race)
Para la prueba de la mediana:
median wage, by(race)
Si preferimos, podemos llamar a las pruebas anteriores con el comando db (dialog box)
Video
lunes, 10 de abril de 2017
Ejercicio. Relaciones entre variables dicotómicas y variables continuas (sin solución).
Para realizar la primera parte de este ejercicio se trabajará con el archivo nlsw88.dta provisto por Stata.
- Abra el archivo nlsw88.dta.
- Indique cuántos casos y cuántas variables tiene.
- Se desea estudiar la relación entre age (edad) y south (vive en el sur o no). La variable south ¿es dicotómica?
- ¿Cuántos casos tiene cada uno de los grupos? ¿Son muestras "grandes"? Explique.
- Grafique la relación entre age y south. Interprete la gráfica.
- Haga una tabla con ayuda del comando tabstat que indique la media de edad de los que viven en el Sur y de los que no viven.
- Asumiendo que estamos en presencia de una muestra aleatoria simple, realice una prueba t con las opciones que correspondan e indique si la diferencia de medias de edad es significativa. Explique.
De aquí en más se trabajará con un archivo creado al efecto.
*************************************************
clear all
set obs 20
set seed 153
gen dieta = 1 in 1/10
replace dieta = 2 in 11/20
gen peso = rchi2(1) * 2 + 10 if dieta == 1
replace peso = rchi2(1) * 2 + 13 if dieta == 2
*************************************************
Imaginemos que se tienen 20 lechones, y a 10 se los alimentó con la dieta 1 y a los otros 10 con la dieta 2.
Se pide:
- Verifique que fueron 10 los lechones alimentados con la dieta 1 y 10 con la dieta 2.
- Grafique la relación dieta - peso e interprete la gráfica.
- Haga una tabla que indique la media de peso para la dieta 1 y para la dieta 2.
- Indique qué prueba de significación haría para establecer si se puede descartar la hipótesis nula de igualdad de medias, y ejecútela.
- Comente los resultados.
miércoles, 5 de abril de 2017
Relaciones bivariadas: variable dicotómica y variable continua. Video
Las variables dicotómicas son variables que pueden tomar exactamente dos valores: sexo (hombre/mujer), estudia (si/no), tiene hijos (sí, no).
En muchas ocasiones interesa ver si dos variables, una dicotómica y una continua están relacionadas.
Un ejemplo: ¿están relacionadas sexo y salario? Esto en general quiere decir: ¿tienen la misma media los salarios de hombres y mujeres?
Otro ejemplo: ¿la altura y el sexo están relacionados? En general esta pregunta la contestamos averiguando si la altura media de los hombres es igual a la altura media de las mujeres.
Otro ejemplo: ¿Trabajan la misma cantidad de horas en promedio quienes tienen hijos que quienes no los tienen?
Para contestar a este tipo de preguntas recurrimos a gráficas tales como diagramas de caja, a tablas producidas por el comando tabstat, a pruebas t de significación y a pruebas no paramétricas con el comando ranksum.
De todo lo anterior tratará este video.
Trabajaremos primero con el archivo nlsw88.dta provisto por Stata, y allí veremos el uso del ttest para grupos independientes (test t de Student para grupos independientes. Allí los grupos comparados son grandes, esto es, cada uno tiene más de 30 observaciones. Veremos dos alternativas de la prueba t: con varianzas asumidas iguales y con varianzas desiguales.
Luego trabajaremos con el archivo generado por la siguiente sintaxis.
********************************************
clear all
set obs 30
set seed 15899
gen valor_hora = 50 + rchi2(2) in 1/15
replace valor_hora = 70 + rchi2(2) in 16/30
gen sexo = 1 in 1/15
replace sexo = 2 in 16/30
label define sexo 1 "Hombre" 2 "Mujer"
label values sexo sexo
set seed 15915
gen notas_geog = rnormal(50, 15)
********************************************
Aquí tendremos muestras pequeñas (15 hombres vs 15 mujeres) y usaremos el ttest o una alternativa no paramétrica, el ranksum, que implementa la prueba de Wilcoxon, casi idéntica a la U de Mann Whitney.
Video
jueves, 30 de marzo de 2017
Ejercicio sobre relaciones bivariadas entre dos variables cuanti (sin solución)
Genere una base de datos ejecutando los comandos que siguen.
***************** Generación de base de datos******************
En videos anteriores se vieron los comandos:
scatter var1 var2 para diagramas de dispersión
lowess var1 var2 para diagramas de dispersión con curva suavizada que acompañe las concentraciones de puntos
twoway (scatter var1 var2) (lfit var1 var2) para diagrama de dispersión con recta de mejor ajuste
pwcorr var1 var2, sig para pedir r de Pearson, que indica qué tan bien se ajusta la nube de puntos a una recta
spearman var1 var2 que indica hasta donde una relación es monótona creciente o decreciente (monotonía perfecta creciente indica que cuando sube una variable siempre sube la otra, y monotonía perfecta decreciente que cuando sube una variable siempre baja la otra. (No usar si es creciente en un tramo de una relación curvilínea y decreciente en otro).
Se pide al estudiante que, haciendo uso de los comandos anteriores, estudie cada una de las relaciones siguientes.
j x
k x
L x
m x
n x
p x
Los tres pasos anteriores se aplicarán primero para la relación jx, luego se aplicarán los mismos tres pasos para kx, etc.
***************** Generación de base de datos******************
clear all
set seed 18964
set obs 600
gen x = (runiform() * 118 + 2)
gen j = 160 - x + rnormal(0, 30)
gen k = 15 + x + round(rnormal(0,8))
gen L = 50 + x + rnormal(0,4)
set obs 601
replace x = 300 in 601
replace L = 58 in 601
replace x = . in 601
gen m = ln(x)
gen n = m + rnormal(0, 0.2)
sum x
gen p = x * 150 - x^2 + rnormal(0, 230)**************Fin generación de base de datos******************
En videos anteriores se vieron los comandos:
scatter var1 var2 para diagramas de dispersión
lowess var1 var2 para diagramas de dispersión con curva suavizada que acompañe las concentraciones de puntos
twoway (scatter var1 var2) (lfit var1 var2) para diagrama de dispersión con recta de mejor ajuste
pwcorr var1 var2, sig para pedir r de Pearson, que indica qué tan bien se ajusta la nube de puntos a una recta
spearman var1 var2 que indica hasta donde una relación es monótona creciente o decreciente (monotonía perfecta creciente indica que cuando sube una variable siempre sube la otra, y monotonía perfecta decreciente que cuando sube una variable siempre baja la otra. (No usar si es creciente en un tramo de una relación curvilínea y decreciente en otro).
Se pide al estudiante que, haciendo uso de los comandos anteriores, estudie cada una de las relaciones siguientes.
j x
k x
L x
m x
n x
p x
- Primero se graficará cada relación, y el estudiante indicará si es una relación lineal o curvilínea, si es creciente o decreciente, o creciente en un tramo y decreciente en otro, y si tiene outliers.
- La fuerza de la asociación se medirá con la r de Pearson si la relación es lineal y con la r de Spearman se medirá el grado de monotonía si la relación es curvilínea creciente o decreciente. (Si es creciente en un tramo y decreciente en otro no se aplicarán ni la r de Pearson ni la rho de Spearman).
- Si hubiere presencia de outliers, las medidas de fuerza de la asociación se calcularán con y sin los outliers.
Los tres pasos anteriores se aplicarán primero para la relación jx, luego se aplicarán los mismos tres pasos para kx, etc.
sábado, 25 de marzo de 2017
Relaciones bivariadas: dos variables cuantitativas (continuación). Video
En este video, se analizarán relaciones entre variables cuantitativas de archivos provistos por Stata. Se verá cómo lucen algunas relaciones menos típicas que en ocasiones aparecen en la vida real.
Video
lunes, 20 de marzo de 2017
Relaciones bivariadas: dos variables cuantitativas (inicio). Video
En este video se verá la relación entre variables cuantitativas.
Primero se estudiarán mediante gráficas de dispersión (scatterplots) y luego se calcularán, si corresponde, dos estadísticos de fuerza de la asociación: r de Pearson y r de Spearman.
Se trabajará con la sintaxis que sigue.
**** inicio generacion base de datos ********
clear all
set obs 50
set seed 8891
gen n = round(rnormal(65,13))
gen notas_matematica = round(n + rnormal(0,5))
gen notas_geometria = round(n + rnormal(0,5))
gen notas_calculo = round(notas_matematica + rnormal(0, 1))
gen notas_teatro = 100 - round(n + rnormal(0,3))
gen notas_fisica = round(n + rnormal(0,2))
gen notas_piano = round(rnormal(65,13))
gen notas_jardineria = round(2.7 * n - 0.02 *n^2 + rnormal(0,1))
drop n
set obs 51
replace notas_fisica = 99 in 51
replace notas_teatro = 99 in 51
******* fin generacion base de datos ********
******* inicio gráficas *********************
******* y medidas de asociación *************
scatter notas_matematica notas_geometria
pwcorr notas_matematica notas_geometria, sig
spearman notas_matematica notas_geometria
scatter notas_piano notas_matematica
pwcorr notas_piano notas_matematica, sig
spearman notas_piano notas_matematica
scatter notas_matematica notas_calculo
pwcorr notas_matematica notas_calculo, sig
spearman notas_matematica notas_calculo
scatter notas_teatro notas_matematica
pwcorr notas_teatro notas_matematica, sig
spearman notas_teatro notas_matematica
scatter notas_fisica notas_teatro
pwcorr notas_fisica notas_teatro, sig
spearman notas_fisica notas_teatro
scatter notas_jardineria notas_matematica
pwcorr notas_jardineria notas_matematica, sig
spearman notas_jardineria notas_matematica
********fin gráficas ************************
******* y medidas de asociación *************
Video
Primero se estudiarán mediante gráficas de dispersión (scatterplots) y luego se calcularán, si corresponde, dos estadísticos de fuerza de la asociación: r de Pearson y r de Spearman.
Se trabajará con la sintaxis que sigue.
**** inicio generacion base de datos ********
clear all
set obs 50
set seed 8891
gen n = round(rnormal(65,13))
gen notas_matematica = round(n + rnormal(0,5))
gen notas_geometria = round(n + rnormal(0,5))
gen notas_calculo = round(notas_matematica + rnormal(0, 1))
gen notas_teatro = 100 - round(n + rnormal(0,3))
gen notas_fisica = round(n + rnormal(0,2))
gen notas_piano = round(rnormal(65,13))
gen notas_jardineria = round(2.7 * n - 0.02 *n^2 + rnormal(0,1))
drop n
set obs 51
replace notas_fisica = 99 in 51
replace notas_teatro = 99 in 51
******* fin generacion base de datos ********
******* inicio gráficas *********************
******* y medidas de asociación *************
scatter notas_matematica notas_geometria
pwcorr notas_matematica notas_geometria, sig
spearman notas_matematica notas_geometria
scatter notas_piano notas_matematica
pwcorr notas_piano notas_matematica, sig
spearman notas_piano notas_matematica
scatter notas_matematica notas_calculo
pwcorr notas_matematica notas_calculo, sig
spearman notas_matematica notas_calculo
scatter notas_teatro notas_matematica
pwcorr notas_teatro notas_matematica, sig
spearman notas_teatro notas_matematica
scatter notas_fisica notas_teatro
pwcorr notas_fisica notas_teatro, sig
spearman notas_fisica notas_teatro
scatter notas_jardineria notas_matematica
pwcorr notas_jardineria notas_matematica, sig
spearman notas_jardineria notas_matematica
********fin gráficas ************************
******* y medidas de asociación *************
Video
viernes, 17 de marzo de 2017
Comandos keep y drop. Video
Los comandos keep y drop sirven para retener o eliminar tanto casos como variables en una base. Keep se usa para retener; drop para eliminar.
Lógicamente, retener unas variables es lo mismo que eliminar otras variables. Lo mismo vale para las observaciones.
Si tenemos hombres y mujeres en nuestra base y deseamos estudiar mujeres, tenemos dos comandos equivalentes:
keep if sexo == "mujer"
o bien
drop if sexo == "hombre"
Los comandos keep y drop actúan también sobre las variables. Supongamos que tenemos las variables W, X, Y y Z.
Si queremos retener con las variables W y X, podemos ejecutar dos comandos equivalentes:
keep W X
o bien
drop Y Z
Video
Lógicamente, retener unas variables es lo mismo que eliminar otras variables. Lo mismo vale para las observaciones.
Si tenemos hombres y mujeres en nuestra base y deseamos estudiar mujeres, tenemos dos comandos equivalentes:
keep if sexo == "mujer"
o bien
drop if sexo == "hombre"
Los comandos keep y drop actúan también sobre las variables. Supongamos que tenemos las variables W, X, Y y Z.
Si queremos retener con las variables W y X, podemos ejecutar dos comandos equivalentes:
keep W X
o bien
drop Y Z
Video
jueves, 16 de marzo de 2017
Ejercicio con condiciones (sin solución)
Corra la siguiente sintaxis y genere una base.
********************************************.
clear all
set obs 400
gen identificacion = _n
set seed 7998
gen aleat = runiform()
gen genero = "terror" if (aleat < 0.10)
replace genero = "policial" if (aleat > 0.10 & aleat < 0.25)
replace genero = "lejano oeste" if (aleat > 0.25 & aleat < 0.40)
replace genero = "romantico" if (aleat > 0.40 & aleat < 0.60)
replace genero = "guerra" if (aleat > 0.60 & aleat < 0.80)
replace genero = "comedia" if (aleat > 0.80 & aleat < 1)
gen duracion_minut = trunc(runiform() * 80 + 60)
replace duracion_minut = . if runiform() < 0.08
gen nacionalidad_director = trunc(runiform() * 7 + 1)
label define nacionalidad_director 1 "inglés" 2 "norteamericano" 3 "indio" 4 "chino" 5 "latinoamericano" 6 "turco" 7 "otro"
label values nacionalidad_director nacionalidad_director
gen entradas_vendidas = trunc(runiform() * 15000000 + 5000000)
gen recibio_premios = runiform() < 0.70
label define recibio_premios 1 "Sí" 0 "No"
label values recibio_premios recibio_premios
drop aleat
cls
********************************************.
La base de datos generada simula las películas a las que pueden acceder tres amigos.
- El primero, Mario, desea ver una película que no sea de guerra, y con un director que no sea inglés ni norteamericano. ¿Cuántas películas son aceptables para Mario?
- Browsee las variables identificación, genero y nacionalidad del director de las adecuados para Mario.
- El segundo, Alberto, desea una película que dure más de 60 minutos. ¿Cuántas películas son aceptables para Alberto?
- Liste las variables identificación y duracion_minut de las aceptables para Alberto.
- El tercero, Miguel, quiere ver una película que tenga premios, y que dure entre 70 y 100 minutos (ambos extremos incluidos). ¿Cuántas películas son aceptables para Miguel?
- Browsee las variables identificacion, duracion_minut y recibio_premios.
miércoles, 15 de marzo de 2017
Ejercicio con condiciones (con solución en video)
Se trabajará con una base que simula el catálogo de una librería.
Allí habrá datos sobre la cantidad de páginas, el tipo de tapa (blanda o dura), el autor (uruguayo, latinoamericano, español o del resto del mundo) y tema (geografía, historia y novelas). La variable libro_nro sirve para identificar a cada libro.
La base se generará ejecutando la siguiente sintaxis:
**********************************************************
clear all
set obs 150
set seed 6678
gen libro_nro = _n
gen cantidad_paginas = round(rnormal(200, 45))
replace cantidad_paginas = . in 12/14
gen tipo_tapa = round(runiform()) + 1
label define tipo_tapa 1 "Tapa blanda" 2 "Tapa dura"
label values tipo_tapa tipo_tapa
gen nac_aut = round(runiform()*3 + 1)
label variable nac_aut "Nacionalidad del autor"
label define nac_aut 1 "Uruguayo" 2 "Latinoamericano" 3 "Español" 4 "Resto del mundo"
label values nac_aut nac_aut
gen tema_libro = round(runiform()*2 + 1)
label define tema_libro 1 "Geografía" 2 "Historia" 3 "Novelas"
label values tema_libro tema_libro
**********************************************************
Se pide al estudiante:
Indique cuáles variables son cuantitativas y cuales categóricas.
Indique cuántas variables hay de cadena y cuántas numéricas.
Indique si hay variables con valores faltantes. Si las hay, indique cuáles son y cuántos son los valores faltantes.
Estela desea regalar un libro de entre 180 y 225 páginas. Browsee los libros adecuados y compruebe que todos tienen la cantidad de páginas adecuada. ¿Cuántos libros se le podrán ofrecer a Estela?
Alberto desea regalar un libro con más de 280 páginas. Haga un listado con los libros deseados por Alberto, con las variables libro_nro y cantidad de páginas. Compruebe que todos sus libros tienen más de 280 páginas.
Miguel desea un libro de historia con tapa dura. Browsee los libros que le servirían a Miguel. Verifique que usted estableció bien las condiciones en su comando. Indique cuántos libros tienen las condiciones solicitadas por Miguel.
Natalia desea un libro de autor o bien latinoamericano o bien español, pero que tenga menos de 140 páginas. Browsee los libros que cumplen con las condiciones de Natalia. Verifique que los libros cumplen con las condiciones requeridas. Indique cuántos libros son.
Sofía quiere un libro cuyo autor no haya nacido en el resto del mundo, ¿Cuántos libros hay en estas condiciones?
Francisco quiere un libro de autor uruguayo o latinoamericano, de tema geográfico o histórico y que tenga más de 260 páginas. Browsee los libros que le servirían a Francisco. Verifique que cumplen las condiciones. Indique cuántos libros son.
Solución en video
Allí habrá datos sobre la cantidad de páginas, el tipo de tapa (blanda o dura), el autor (uruguayo, latinoamericano, español o del resto del mundo) y tema (geografía, historia y novelas). La variable libro_nro sirve para identificar a cada libro.
La base se generará ejecutando la siguiente sintaxis:
**********************************************************
clear all
set obs 150
set seed 6678
gen libro_nro = _n
gen cantidad_paginas = round(rnormal(200, 45))
replace cantidad_paginas = . in 12/14
gen tipo_tapa = round(runiform()) + 1
label define tipo_tapa 1 "Tapa blanda" 2 "Tapa dura"
label values tipo_tapa tipo_tapa
gen nac_aut = round(runiform()*3 + 1)
label variable nac_aut "Nacionalidad del autor"
label define nac_aut 1 "Uruguayo" 2 "Latinoamericano" 3 "Español" 4 "Resto del mundo"
label values nac_aut nac_aut
gen tema_libro = round(runiform()*2 + 1)
label define tema_libro 1 "Geografía" 2 "Historia" 3 "Novelas"
label values tema_libro tema_libro
**********************************************************
Se pide al estudiante:
Indique cuáles variables son cuantitativas y cuales categóricas.
Indique cuántas variables hay de cadena y cuántas numéricas.
Indique si hay variables con valores faltantes. Si las hay, indique cuáles son y cuántos son los valores faltantes.
Estela desea regalar un libro de entre 180 y 225 páginas. Browsee los libros adecuados y compruebe que todos tienen la cantidad de páginas adecuada. ¿Cuántos libros se le podrán ofrecer a Estela?
Alberto desea regalar un libro con más de 280 páginas. Haga un listado con los libros deseados por Alberto, con las variables libro_nro y cantidad de páginas. Compruebe que todos sus libros tienen más de 280 páginas.
Miguel desea un libro de historia con tapa dura. Browsee los libros que le servirían a Miguel. Verifique que usted estableció bien las condiciones en su comando. Indique cuántos libros tienen las condiciones solicitadas por Miguel.
Natalia desea un libro de autor o bien latinoamericano o bien español, pero que tenga menos de 140 páginas. Browsee los libros que cumplen con las condiciones de Natalia. Verifique que los libros cumplen con las condiciones requeridas. Indique cuántos libros son.
Sofía quiere un libro cuyo autor no haya nacido en el resto del mundo, ¿Cuántos libros hay en estas condiciones?
Francisco quiere un libro de autor uruguayo o latinoamericano, de tema geográfico o histórico y que tenga más de 260 páginas. Browsee los libros que le servirían a Francisco. Verifique que cumplen las condiciones. Indique cuántos libros son.
Solución en video
viernes, 10 de marzo de 2017
Valores faltantes (missing). Video
Este video se realizó con una base surgida de la siguiente sintaxis:
************************************************
clear all
set seed 2145
set obs 400
gen caso_nro = _n
gen tiempo_reaccion = round(rnormal(35,8))
replace tiempo_reaccion = . if runiform() < .05
replace tiempo_reaccion = .a if runiform() < .03
label define tiempo .a "No concurrió a prueba"
label value tiempo_reaccion tiempo
gen deporte = int(runiform() * 3)+ 1
label define deporte 1 "Futbol" 2 "Basquetbol" 3 "Otro"
label value deporte deporte
replace deporte = . if runiform() < 0.10
gen nacionalidad = "uruguayo"
replace nacionalidad = "" in 1/3
replace nacionalidad = "argentino" in 5/8
************************************************
Se verá cómo se presentan los valores faltantes en la base de datos y las precauciones que hay que tener cuando se piden condiciones "mayores que".
Video
************************************************
clear all
set seed 2145
set obs 400
gen caso_nro = _n
gen tiempo_reaccion = round(rnormal(35,8))
replace tiempo_reaccion = . if runiform() < .05
replace tiempo_reaccion = .a if runiform() < .03
label define tiempo .a "No concurrió a prueba"
label value tiempo_reaccion tiempo
gen deporte = int(runiform() * 3)+ 1
label define deporte 1 "Futbol" 2 "Basquetbol" 3 "Otro"
label value deporte deporte
replace deporte = . if runiform() < 0.10
gen nacionalidad = "uruguayo"
replace nacionalidad = "" in 1/3
replace nacionalidad = "argentino" in 5/8
************************************************
Se verá cómo se presentan los valores faltantes en la base de datos y las precauciones que hay que tener cuando se piden condiciones "mayores que".
Video
domingo, 5 de marzo de 2017
Condiciones en Stata. if. Operadores relacionales y lógicos. Video
En este video se trabajará con la base de datos que surge de la siguiente sintaxis:
************************************************
clear all
set seed 2145
set obs 400
gen nro_caso = _n
gen colorpelo = int((runiform()*4))+ 1
label define colorpelo 1 "rubio" 2"pelirrojo" 3 "castaño" 4 "negro"
label values colorpelo colorpelo
label variable colorpelo "Color de pelo"
gen altura = round(rnormal(173,6))
gen aleat = runiform()
gen nov_pref = "policial" if aleat < 0.10
replace nov_pref = "ciencia ficcion" if aleat >= 0.10 & aleat < 0.40
replace nov_pref = "romantica" if aleat >=0.40 & aleat < 0.70
replace nov_pref = "historica" if aleat >=0.70 & aleat <= 1
label variable nov_pref "Tipo de novela preferida"
drop aleat
gen sueldo = int(rnormal(200, 15))
gen patrimonio = rnormal(45000, 8200)
************************************************
Se mostrará cómo trabajar con condiciones. Saber cómo trabajar con ellas es una habilidad crítica para quienes realizan análisis de datos.
Se mostrará cómo trabajar con los siguientes operadores:

Video
domingo, 26 de febrero de 2017
Ejercicio de revisión (sin solución)
Genere una base de datos corriendo la sintaxis que sigue:
A continuación, conteste las siguientes preguntas:
************************************************
clear
all
set
seed 2145
set
obs 400
gen
nro_caso = _n
gen
vida_luego_muerte = int((runiform()*4))+ 1
label
define vida_luego_muerte 1 "sí, definitivamente" 2"si,
probablemente" 3 "probablemente no" 4 "no,
definitivamente"
label
values vida_luego_muerte vida_luego_muerte
label variable vida_luego_muerte "Hay vida después de la muerte?"
label variable vida_luego_muerte "Hay vida después de la muerte?"
gen
altura = round(rnormal(173,6))
gen
aleat = runiform()
replace
aleat = . if runiform() < 0.10
gen
gente_abusa = "todo el tiempo" if aleat < 0.10
replace
gente_abusa = "la mayoría del tiempo" if aleat >= 0.10
& aleat < 0.30
replace
gente_abusa = "pocas veces" if aleat >=0.30 & aleat
< 0.70
replace
gente_abusa = "casi nunca o nunca" if aleat >=0.70 &
aleat <= 1
label
variable gente_abusa "La gente abusa de su prójimo ….."
drop
aleat
gen
edad = int(runiform() * 40 + 18)
replace
edad = . if runiform() < 0.05
gen
religion= rbinomial(3, 0.5)
replace
religion = . if runiform() < 0.10
label
define religion 0 “hinduismo” 1 “sintoísmo” 2
“neopaganismo” 3 “budismo”
label
values religion religion
************************************************
A continuación, conteste las siguientes preguntas:
- ¿Cuántas variables hay en la base?
- ¿Cuántos casos hay?
- ¿Cuántas variables cuantitativas hay? ¿Cuáles son?
- ¿Cuántas variables categóricas hay? ¿Cuáles son?
- Las variables categóricas generalmente están almacenadas como variables numéricas con etiquetas. Sin embargo aquí una de las variables categóricas está almacenada en formato string (cadena). ¿Cuál es?
- La variable altura, ¿es normal?
- Pida la media y la desviación estándar para altura.
- Pida un resumen de 5 puntos para la variable edad.
- Grafique, con una gráfica pertinente, la variable religión. Indique cuál es la categoría más numerosa.
- Pida una nueva gráfica de la variable religión, pero ahora ordenando las barras según frecuencia de casos [catplot religion, var1opts(sort(1) descending)]
- Haga una tabla de frecuencias de la variable religion. Verifique que la categoría más numerosa es la indicada en la gráfica.
- Grafique la variable gente_abusa.
- Pida un listado de frecuencias de dicha variable.
sábado, 25 de febrero de 2017
Ejercicio de revisión (con solución en video)
Ejecute la sintaxis que sigue, la cual creará una base de datos:
************************************************
clear all
set seed 2145
set obs 400
gen nro_caso = _n
gen colorpelo = int((runiform()*4))+ 1
label define colorpelo 1 "rubio"
2"pelirrojo" 3 "castaño" 4 "negro"
label values colorpelo colorpelo
label variable colorpelo "Color de pelo"
label variable colorpelo "Color de pelo"
gen altura = round(rnormal(173,6))
gen aleat = runiform()
gen nov_pref = "policial" if
aleat < 0.10
replace nov_pref = "ciencia
ficcion" if aleat >= 0.10 & aleat < 0.40
replace nov_pref = "romantica"
if aleat >=0.40 & aleat < 0.70
replace nov_pref = "historica"
if aleat >=0.70 & aleat <= 1
label variable nov_pref "Tipo de
novela preferida"
drop aleat
gen sueldo = int(rnormal(200, 15))
gen patrimonio = rnormal(45000, 8200)
************************************************
A continuación, conteste las siguientes preguntas:
- ¿Cuántas variables hay en la base?
- ¿Cuántos casos hay?
- ¿Cuántas variables cuantitativas hay? ¿Cuáles son?
- ¿Cuántas variables categóricas hay? ¿Cuáles son?
- Las variables categóricas generalmente están almacenadas como variables numéricas con etiquetas. Sin embargo aquí una de las variables categóricas está almacenada en formato string (cadena). ¿Cuál es?
- La variable patrimonio, ¿es normal?
- La variable sueldo, ¿es normal?
- Pida las medidas de resumen para las variables patrimonio y sueldo que estime pertinentes. (Se recuerda que las medidas de resumen para variables cuantitativas más habituales son, o bien media y desviación estándar o bien resumen de 5 puntos).
- Grafique, con una gráfica pertinente, la variable colorpelo. Indique cuál es la categoría más numerosa.
- Haga una tabla de frecuencias de la variable colorpelo. Indique cuál es la categoría más numerosa.
Video con solución
Suscribirse a:
Entradas (Atom)